- Choosing the correct technologies from the very beginning can save up lots of time and headaches.
- Switching technology later on when the production system is running is very hard and only done if it defines business’s survival
- I am always interested in which use cases were anticipated (or did not anticipate when chosing certain technologies)
- I have heard RabbitMQ being used in several teams but did not know what are its drawbacks. So this was a very good article to glean on.
- Trello had several iterations of changing queues before finally moving over to Kafka,
- Redis Pub/Sub solution.
- RabbitMQ
- Finally Kafka
- This is a self-managed solution.
- Sounds similar to train stations. Or spaceship docking stations. Except the trains or ships can occasionally explode. More on that is below.
- RabbitMQ basics:
- Exchange – Entry point, works like a proxy. The train station
- Queue – Holds the messages. The train itself
- Binding – Holds the connection between exchange and queues. The train tracks
- Routing policy – The policy decides how a message gets sent from the exchange to queues. The goods.
- Routing policies as 4 common flavors:
- Fanout – just send messages to all queues ignoring routing keys
- Direct – send messages to queues that have matching routing key/binding key
- Topic – A wildcat matching of routing and binding key. (Sounds like normal regex with *)
- Headers – Use the headers
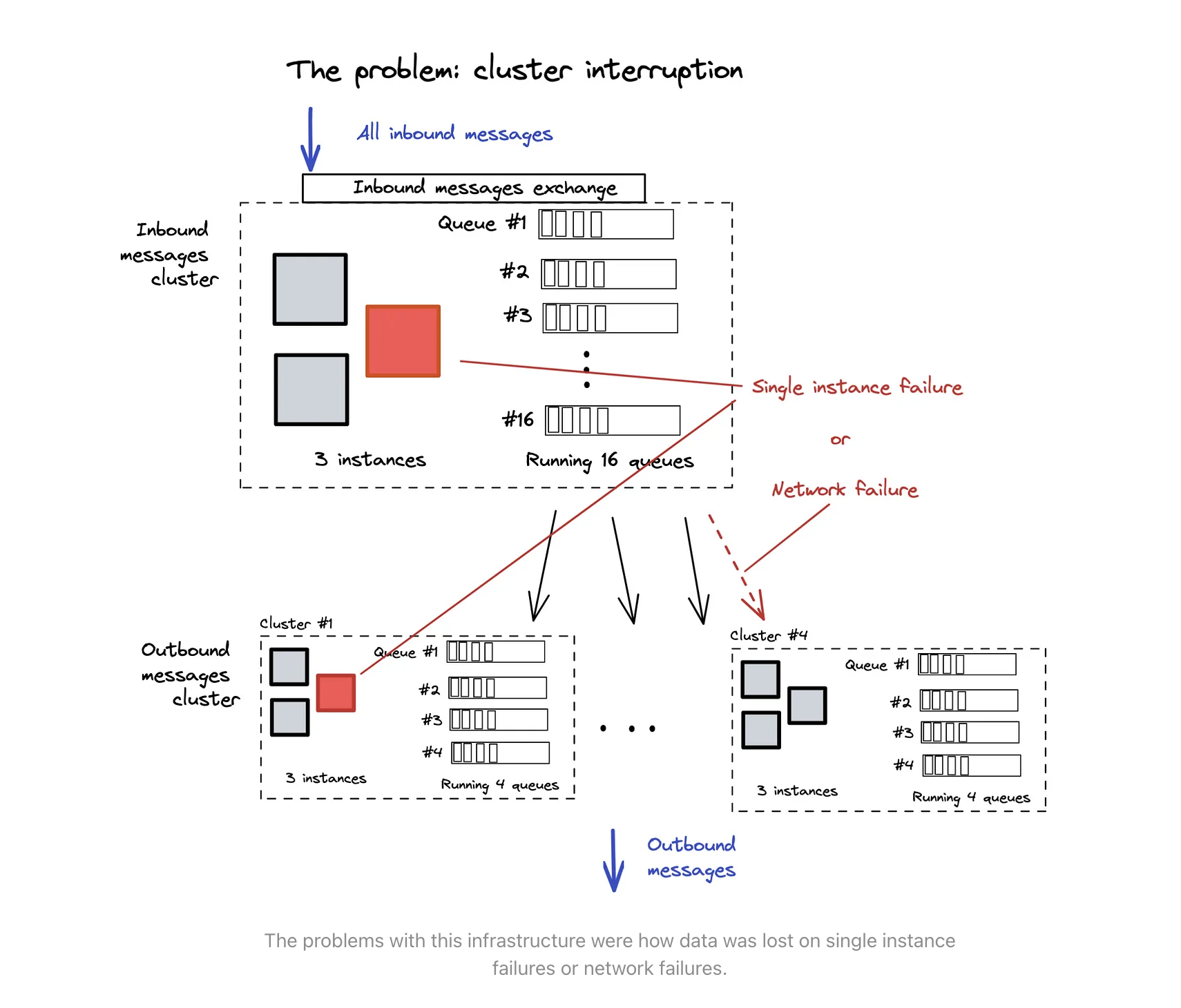
- Queues are transient in RabbitMQ, they get destroyed as soon as the TCP connection that created them closes. (This is a super big drawback from what I know about queues. Queues should not be easily destroyed by unknown factors such as bad network, or hardware failures.)

RabbitMQ implementation looks like a separation of concern however, when there are any issues during the operation, there is a synchronous failure on many parties. Hence RabbitMQ is not exactly an ideal distributed queue system.
Bad things happen when a failure occurs:
- RabbitMQ needs to do a full reset
- Force clients to reconnect
- It takes a long time for queues to be recreated, this could be unavailabilities for certain services.
- Messages are lost (if there are no fallback plans outside of the RabbitMQ solution)
Three ways a failure can occur:
- One of the instances within a cluster group dies in the exchange
- One of the instances within a cluster group dies in the outbound message center
- The binder has network issues and is not able to connect to the target message queue with the exchange cluster.
Network issues happen very frequently, I am not sure how engineers are using this…
The requirement for the next technology:
- Failover capabilities
- In-order message delivery per shard
- Supports fanout message distribution
- Low latency
- Supports required throughput of 2,000 messages/second
- In my opinion, most technologies support their requirements except for the “in-order” message delivery. This is difficult to achieve in distributed systems and remains highly performant. Some level of performance has to be decreased such as buffer time to hold messages temporarily and examine the ordering.
List of solutions under consideration

Chosen Technology
- Kafka and Redis Streams fit their needs. However, because Redis Streams is still not production battle-tested, Kafka was chosen instead.
- Trello originally moved from Redis Pub/Sub solution to RabbitMQ due to Redis PubSub not guaranteeing message delivery.
- In general, Redis Pub/Sub is a poor choice of technology to be used as a queue. Unless losing messages is OK occasionally.
Ref:

Leave a comment