- Context: The Big Data platform at Uber where logs are generated by hundreds of thousands of Spark Jobs.
- On peak day 200k TB of data would be generated
- The cost of maintaining these logs became so high, it would cost Uber $1.3million per year to keep 1 month worth of log, or $180k to keep 3 days worth of log.
- Traditional tools cannot handle the scale of of this use case such as Elastic Search, and Gzip.
- The use case was to reduce logging storage but at same time being able to search in them. A tool called CLP was discovered.
- Traditional compression like Gzip, Zlib, Zstandard, does not offer this functionality as once you compress logs, you need to uncompress them, then be able to search for specific texts. This is also not feasible for certain logs when uncompressed, consumes large amount of memory.
Logging Architecture
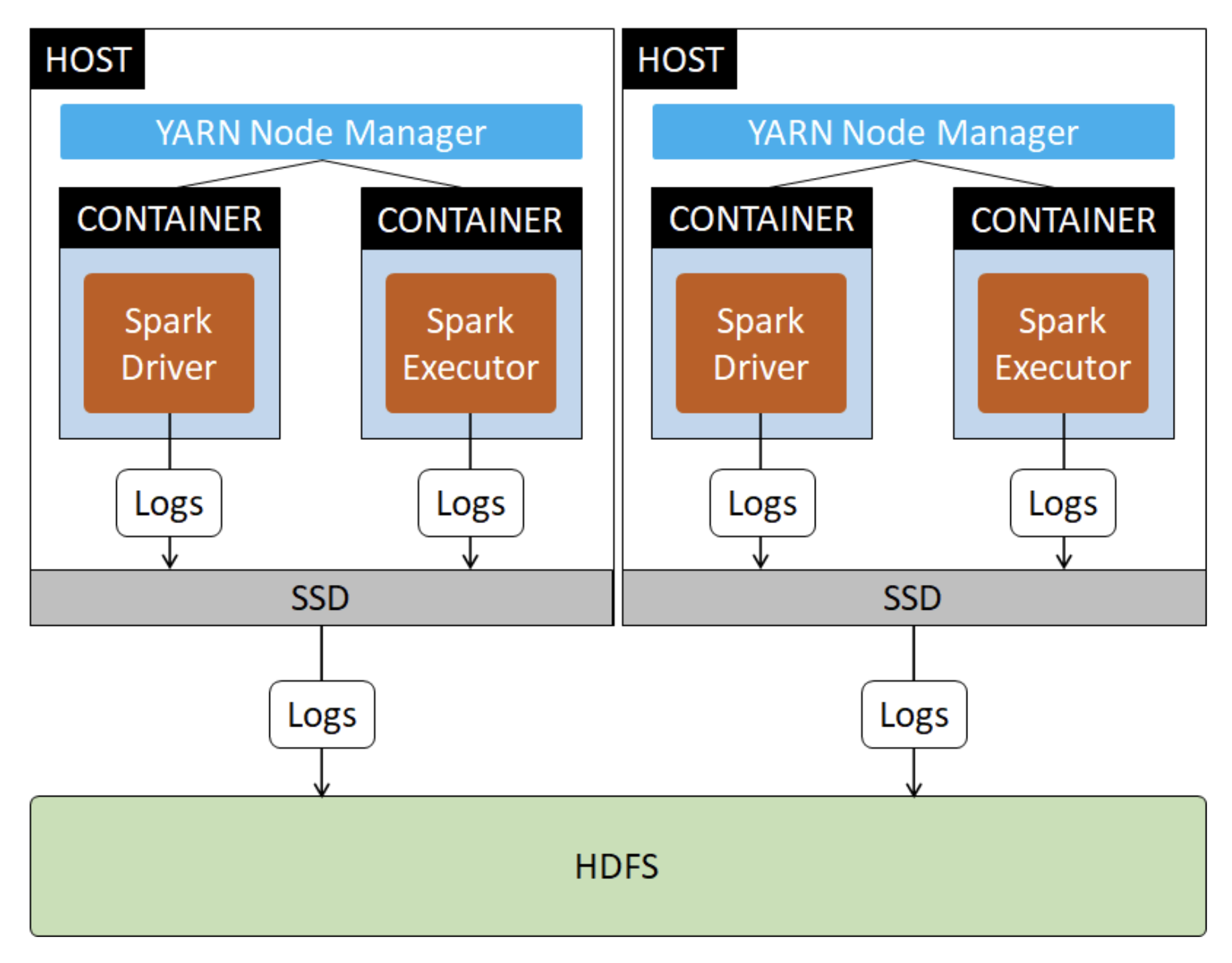
- During execution, the Spark job generates logs. These logs are stored into SSD
- Logs are written using popular library Log4j. Log4j is easily customisable on how logs can be formatted and sent to locations.
- After the Spark job completes, the logs on the SSD are then stored into HDFS via Yarn. Yarn has a log aggregator functionality.
How CLP Works

- parsing – determine which values are likely unique and which values are not unique. Puts them in a table of columns of K/V pairs.
- encoding – convert texts to certain encoding and ids
- dictionary dedup – a given stream of logs have duplicate values. Deduplicate them and also deterministically to reverse this later through other representations.
- column compression – the logs are formatted into table of columns. The values are then compressed using zstandard. I believe it is just using Zstandard compression, not using ZStandard + Table compression (another feature offered in Zstandard).
- In general, CLP works well with logs because some logs are quite repetitive and the dedup functionality in CLP definitely helps. Zstandard also has very high compression ratio
- However for the last step to work really well, there should be right amount of buffer of log conversions before compressing to Zstandard. (I believe steps 1-3 are still searchable, not step 4).
- Hence you would bucket the sizes of your logs in the memory buffer for awhile. You cannot just convert each log statements using CLP immediately.
CLP Implementation in Hadoop Environment
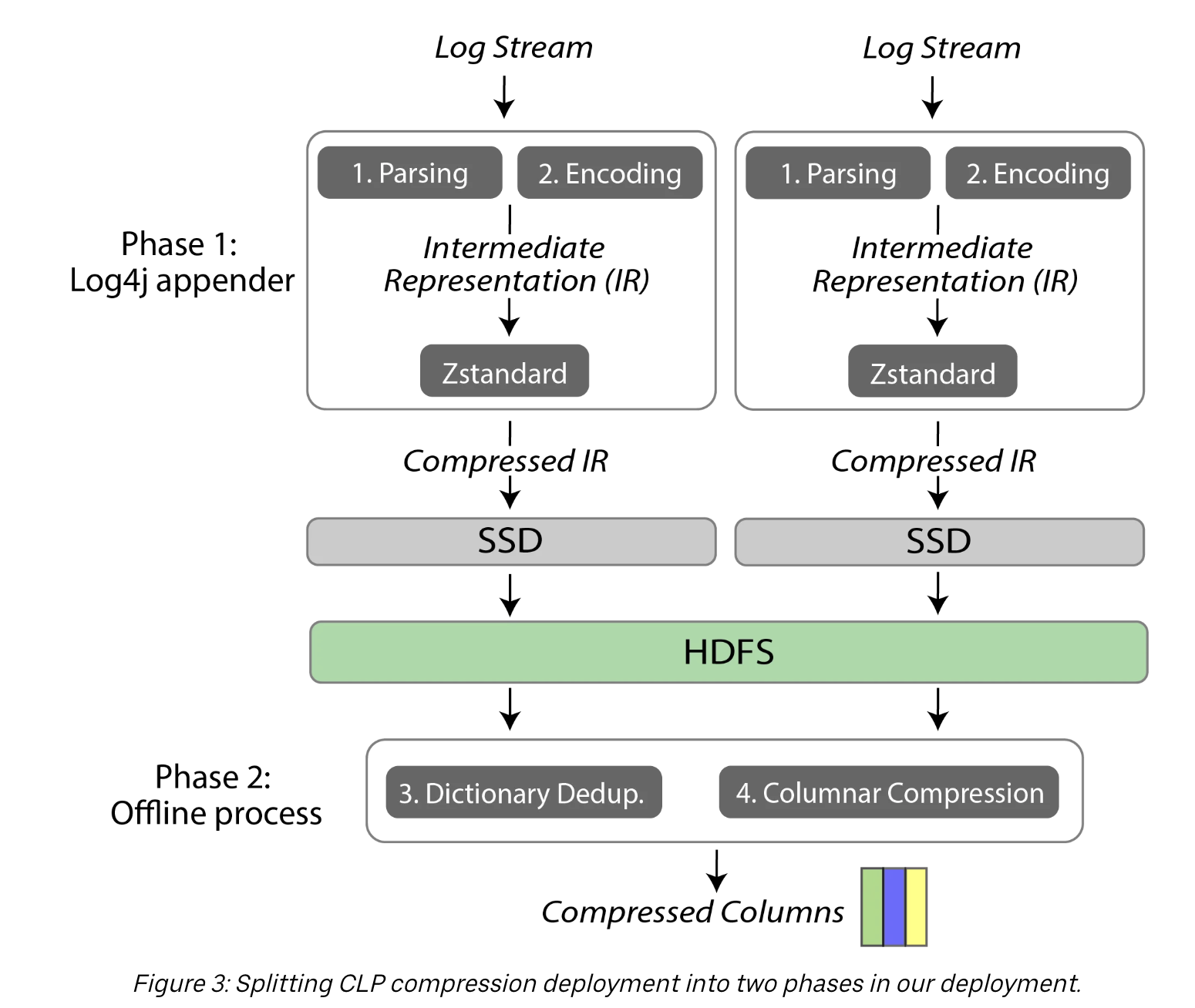
- Uber had to implement CLP with a lot of customisations.
- Steps 1-2 can be done at the host level
- After steps 1-2, they immediately compress the converted values to zstandard.
- The main point is memory are valuable in Spark nodes, and CPU is cheap.
- Compressed logs are written with 4MB at a time to disk.
- Had to write to disk first as some functionalities in hadoop toolsets expected data to be in local disk or hdfs.

- Steps 3-4 needs to be done at the HDFS as the compression/table conversion will be poor if it is kept at the host level.
- Interesting part of the whole process is the parsing is the slowest
- ZStandard is used twice. One at the end of step 2 and one at the end of step 4.
Invented Custom Floating Point Encoding
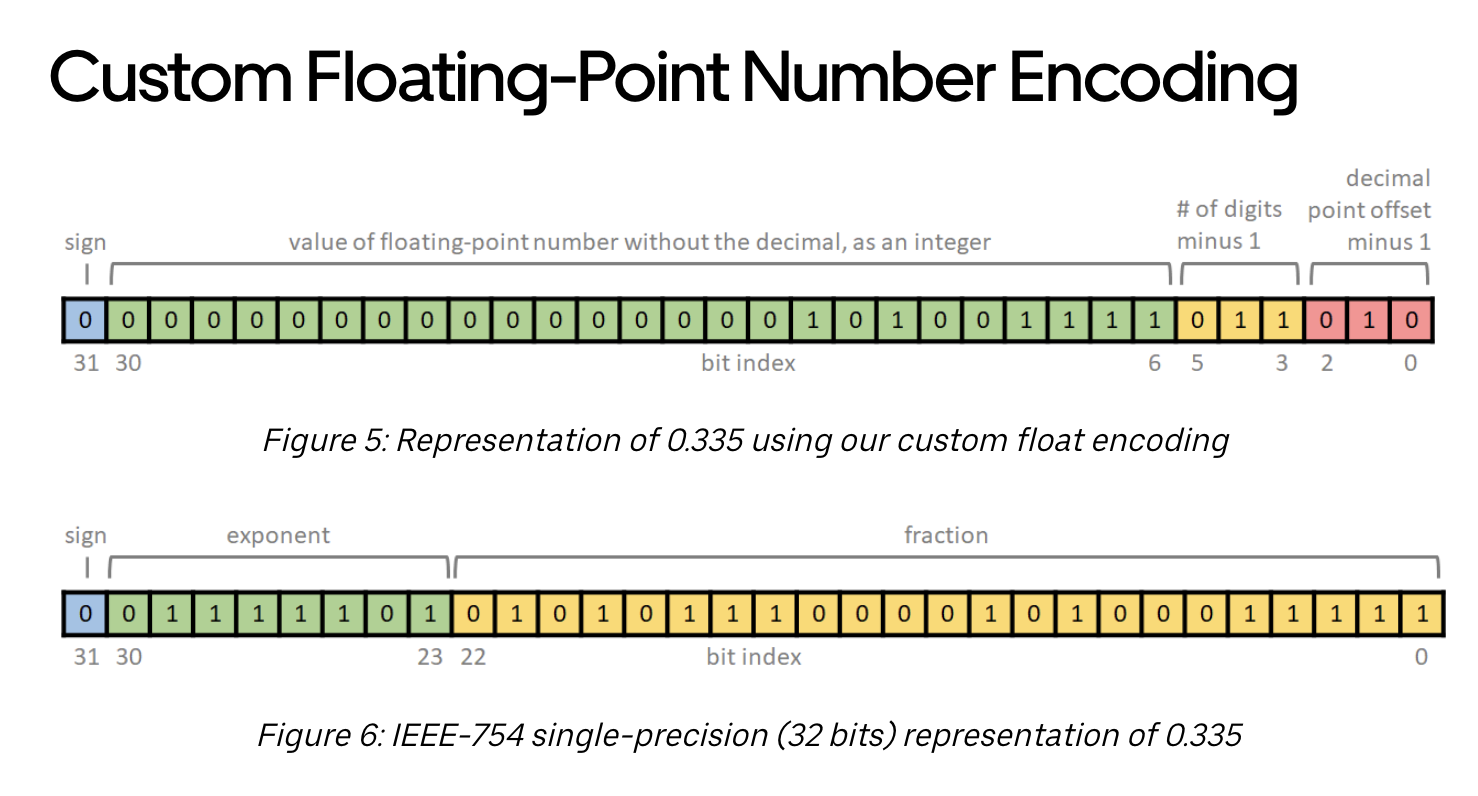
- How custom encoding works:
- 1 bit (b31): Is negative
- 25 bits (b30-6): The value of the floating point number without the decimal point and without the sign, as an integer. For example, for 0.335, these 25 bits represent the value of 335.
- 3 bits (b5-3): The total number of printed digits, minus 1. Thus, it can represent a value with a total number of digits between [1, 8], mapped to the range [0, 7]. In the case of “0.335”, there are a total of 4 digits, so the value of these 3 bits is 3. We use three bits because a 25-bit number has at most 8 decimal digits (2^25 -1 = 33,554,431).
- 3 bits (b2-0): Offset of the decimal point, from the right, minus 1. For example, for 0.335, the offset of the decimal is 3. Note that we take the offset from the right instead of the left because a negative sign might “waste” a value if we do so from the left. For example, if we count from the left, then the offsets of the decimal are different for 0.335 and -0.335, but they’re the same when counting from the right.
- Custom float encoding is invented due to
- IEEE-754 is slow during encoding/decoding
- IEEE-754 is lossy and the custom one is lossless. Ex: Original value is “2.3456789”. With IEEE-754, this becomes 2.3456788”, but with custom, it keeps original value.
- 2-3 times faster
- Couple more differences:
- Custom encoding will work well for between values [-(2^25-1), (2^25-1)]. Outside of this value, it will be treated as dictionary variable (in CLP)
- The encoding works on any strings that has numbers in it. (examples include “23:59:59” or “2.4.3-uber-159”)
Finally:
- Work is divided into two phases.
- Phase 1 (completed)- deploy the Log4j changes to spark nodes and compression locally
- Uncompressed INFO logs are 5.38PB
- Phase 1, compressed logs are 31.4 TB == 169x Compression ratio
- Phase 2 (in progress)- deploy the CLP steps 3-4 changes to the hdfs hadoop environment and allow observability tools to search the logs.
- Phase 1 (completed)- deploy the Log4j changes to spark nodes and compression locally
Ref:
Lossless vs lossy compression

Leave a comment