- The story comes from Pinterest in Mid 2020 that used Kafka to publish Logging data to interested parties.
Data Flow
- Systems generating data –> Producer Logging Platform –> Pub/Sub (Kafka) –> Consumer Logging platform–> Extract data from related systems
- Had some issues around:
- Separating storage and serving components which may have different parameters and requirement
- Custom replications and rebalancing is expensive
- Ordering on read instead of write flexibility helps certain use cases
- Don’t need all the features of Kafka provides:
- Kafka processes stream of data in realtime/low latency. Wanted to use Pub/Sub that does not require such performance.
- Strict Ordering not needed in most cases.
- Enters MemQ
- Used MemQ to separate Storage and Serving messages. Namely Reading data and Writing data can be scaled independently. MemQ has a pluggable feature to do this.

- Since streams of logs were sent into Kafka before, MemQ had to break the stream into a series block of objects and then stored them individually.
- Allows batching sizes that can change end to end latency as needed. Higher latency > less IOPS and cheaper. Lower latency < more IOPS required and instances
MemQ Components
- Client – Clients of MemQ connects to a seed node that returns a set of meta data. Mostly to get the address of the notification Queue to subscribe to it.
- Broker – The Handles the writing of the messages to the storage. The primary storage for Pinterest is S3 AWS.
- Cluster Governor – master/leader for balancing Topic processor. This is one of the Brokers actually, not something dedicated. One of the brokers can get elected .
- ZooKeeper – Config management for MemQ. Used for electing Cluster Governor.
- Topic & Topic Processor – A module within the Broker that can host one of more Topics. TopicProcessors has read/write partitions
- Read partitions handles level of parallelism required by consumers.
- Write partitions handles the write to storage.
Storage
- S3 is used for storing the object itself. The objects have configurable sizes to buffer before writing to S3. S3 has builtin replication and cost effective, however high latency
- Notification Queue – Once an object is written to S3, the metadata is sent to Kafka for the subscribers to fetch information from S3. It’s mentioned that it is used for storage, so wonder if small messages are still just being sent to Kafka directly.
MemQ Data format
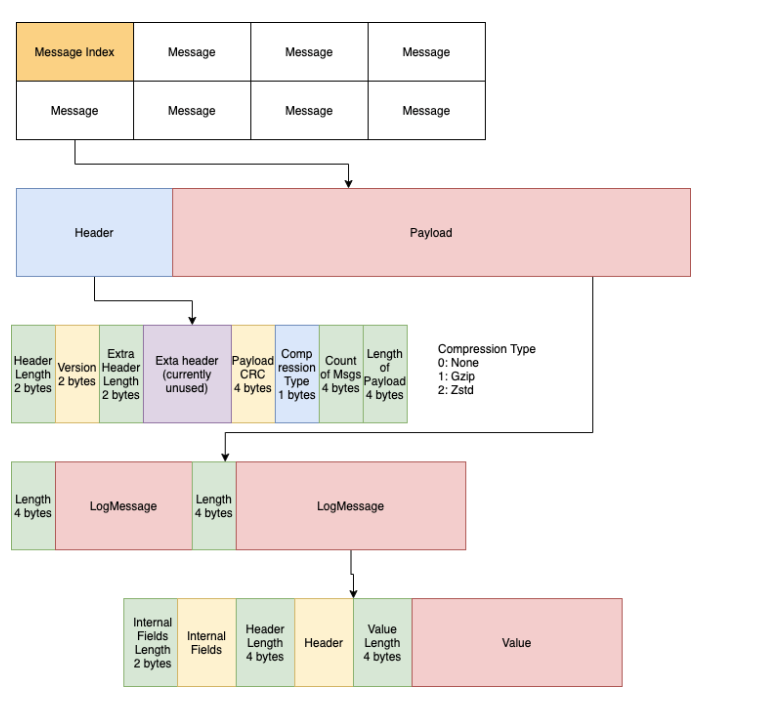
- As we know S3 is impressive, however it also has high latency. MemQ uses an async dispatch model to write the data allow non-blocking sends for the producers does not have to wait for S3 upload to complete before moving to next messages. Below are the available styles of writing:
- ack=0 (producer fire & forget)
- ack=1 (Broker received)
- ack=all (storage received)
- Writes can be batched, or time based buffered. MemQ Topic Processor uses something like a RingBuffer (Circular Buffer?)
- Consumers can read the data from MemQ, or S3 directly. Current architecture uses poll based interface.
- Data Loss Detection – MemQ has built in auditing system that enables tracking E2E message delivery
Takeaways:
- The implementation of MemQ seems like some kind of Data aggregator and controlling how/where data is stored. The use case is similar to Cribl, something Autodesk used when I worked there.
- Since S3 is slow, need to pay special attention to scaling up the write throughput in MemQ.
- Pinterest saved up to 90% by switching to S3 for data storage. Because Kafka requires spinning up more instances to handle large data sets. Storage capacity was more important than speed throughput.
References:

Leave a comment