- Data Mesh platform – an in-house built solution for handling Change Data Capture design patterns for processing data from a source to a target
- Seems to be a real time type of processing job in comparison batch job compared to Hadoop Hive or Spark which achieves similar use cases related to ETL pipelines.
- The solution @ Netflix is developer friendly
- Events can be sourced from generic applications, not only databases (logging, manual data capture, metrics)
- However the list of source data are growing like CockroachDB, Cassandra, Mysql, Postgresql
- The Target a datastore that can be Elastic Search, IceBerg, or separate Kafka Topic.
- The processor is a Flink Job. Apache Flink Job is a data stream processor that handles ETL.
- Events can be sourced from generic applications, not only databases (logging, manual data capture, metrics)
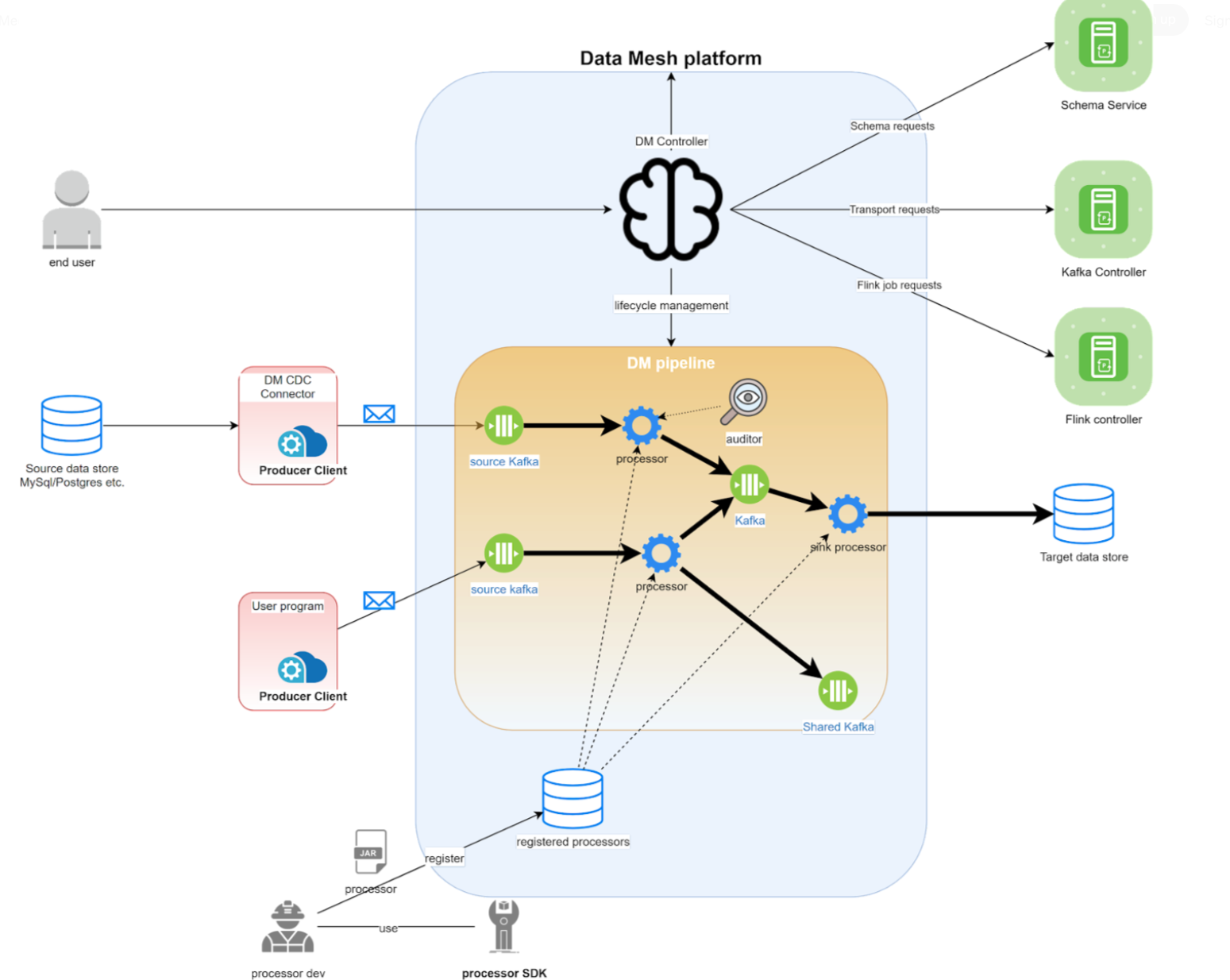
- Sources – Custom events created using CDC connector or database changes itself
- Connectors – a source connector that is a “producer” into the data mesh platform. An example is a CDC event from Postgresql listening to a bin/log.
- Processors – This is a Flink job that can process a topic, and post to another topic for a separate Flink job to continue. A processor SDK was exposed which also allows other Netflix developers to register on the platform and configure changes. (This is cool)
- Schema – Both producer and consumer needs to have a schema. Avro is used for JSON schema validations. This brings the following benefits:
- Consumer gain more confidence as they know what they’re getting from the producer
- Netflix built some kind of UI to track which fields are used by which consumer and show it
- Schema allows new users to browse and discover the underlying data.
- Transport – Kafka is used to decouple producers and consumers. There is a frequent use case for one of the producers to publish to topic #1 which will then be consumed by another processor and outputs it to topic #2

Takeaways:
- Data Mesh still is in early stages, does not seem to be the “recommended solution” for data movement and processing yet.
- Need to find other ways to aggregate Flink Jobs and reduce redundancy
- There is strong use case to move datastore x and move it to datastore y. (Sounds like Cribl use case again). Need to build more connectors.
- While the design of Data Mesh is certainly interesting – developers get to design the pub sub workflows and process data in between, I can see it could become a spaghetti of redundant topics/jobs as more developers onboards it. The maintenance would be a continued effort.
Ref:

Leave a comment