
- Raft is a log replication consensus algorithm used in many distributed databases such as:
- etcd
- CockroachDB
- TiKV
- InFluxDB
- Consul
- HashiCorp
- Kafka
- Dgraph
- It may be worthwhile to look into Raft as some of these databases are able to claim fault tolerance, high availability due to using Raft.
- It is also worthwhile to see the short comings of Raft as the system can go into error state if there are sustained network issues or majority of the nodes are down.
- Log Replication is a method of saving records across many nodes. Each node has a copy of their own log of what is committed and new record entries. Raft attempts to resolve these differences.
- Raft was inspired by Paxos which is another consensus algorithm but a lot more difficult to understand and implement. Raft simplifies the approach which leads to its popularity as it was easier to understand.
Concepts of Raft
- Each node in a cluster can become either a “leader”, “follower”, or “candidate”. It’s a very democratic approach of attempting to achieve consistency.
- leader – the leader node is the receiver of client requests. Given a record need to be updated, this information is routed to the leader node. The leader node then add this to its log and push notifications for the rest of the nodes to replicate similar record.
- follower – when a leader is elected, the rest of the nodes are followers for a given cluster.
- Followers receives request from the leader to replicate changes from the leader. Once the follower have a copy in their log it sends the request back to leader.
- If the leader has a majority of the nodes acknowledging success of the replication (51%), then the record can now be commited. The leader will send the notification to the rest of the followers for the record to be committed.
- Once the follower receive this committed notification, the cluster has achieve consistency of the record.
- candidate – leader node sends “heartbeat” to the rest of the nodes to maintain the leadership state. If the heart beat stops after certain time, then a leader election may begin. In this process, some of the follower nodes transition into “candidate” node where it attempts to elect itself to become the leader.
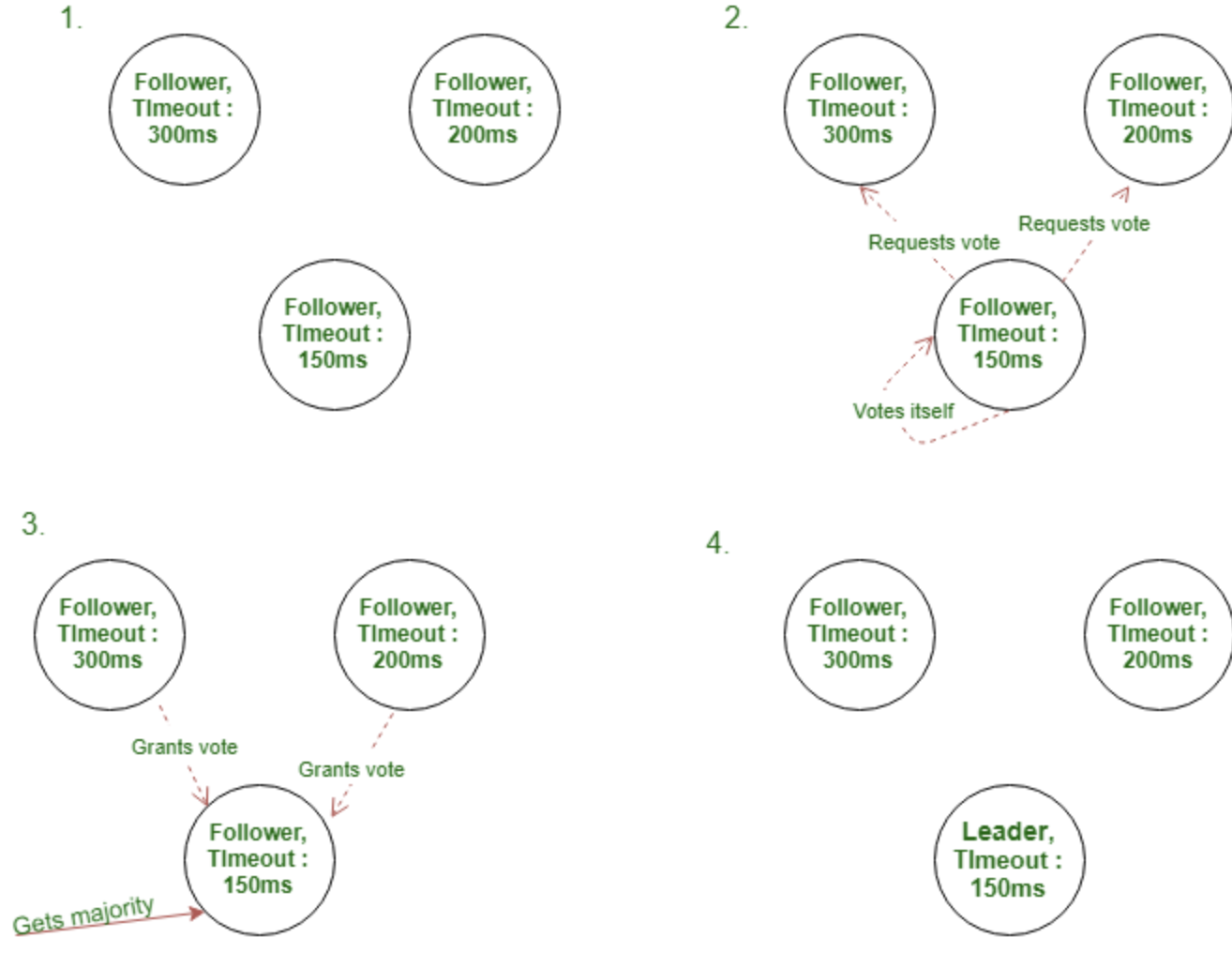
- To become a candidate, followers have a randomized timeout that expects a heartbeat from the leader node. The timeout is typically between 150-300ms.
- It elects itself by sending notification to the rest of the nodes to get the votes. If majority of the nodes respond on time and provides approval, then the candidate node becomes the leader node.
- It is possible for several “candidate” nodes to exist at the same time and try to elect for itself. Based on the randomized timeout mentioned earlier, in addition to getting approval from the majority of other nodes, the candidate node that has the best “network performance” may have the higher chance of becoming the leader node.
- One downfall of this election system is if 51% of the nodes are out of service, a leader will never get elected, the system will break down. Hence it may be wise to spread out nodes across different risk barriers like network, geographical location, deployments of complex configurations to ensure none of these areas of nodes fall into “one kind of basket” while achieving good intranet latencies.
Rules for Safety in the Raft protocol
The Raft protocol guarantees the following safety against consensus malfunction by virtue of its design :
- Leader election safety – At most one leader per term)
- Log Matching safety(If multiple logs have an entry with the same index and term, then those logs are guaranteed to be identical in all entries up through to the given index.
- Leader completeness – The log entries committed in a given term will always appear in the logs of the leaders following the said term)
- State Machine safety – If a server has applied a particular log entry to its state machine, then no other server in the server cluster can apply a different command for the same log.
- Leader is Append-only – A leader node(server) can only append(no other operations like overwrite, delete, update are permitted) new commands to its log
- Follower node crash – When the follower node crashes, all the requests sent to the crashed node are ignored. Further, the crashed node can’t take part in the leader election for obvious reasons. When the node restarts, it syncs up its log with the leader node
Raft Alternatives
- Paxos: Paxos is a consensus algorithm that was developed before Raft. It is known for its simplicity and effectiveness, but can be challenging to understand and implement correctly.
- Zab: Zab is a consensus algorithm used by Apache ZooKeeper. It is similar to Paxos in terms of its complexity and effectiveness, but has some additional features that make it well-suited for use in distributed systems.
- Byzantine Fault Tolerance (BFT): BFT is a family of consensus algorithms that can tolerate faulty or malicious nodes in the system. This can make it particularly useful for applications where security and fault tolerance are critical.
- Practical Byzantine Fault Tolerance (PBFT): PBFT is a specific BFT algorithm that is designed to be practical for use in real-world distributed systems. It is known for its high performance and effectiveness in tolerating faulty nodes.
- HoneyBadgerBFT: HoneyBadgerBFT is a BFT algorithm that is designed to be highly scalable and efficient. It uses a unique approach to consensus that enables it to achieve high performance and fault tolerance.
Fault Scenarios
Q: What happens when one of the nodes have network issues for extended amount of time?
A: Assuming a majority consensus consistency is still able to commit records for the rest of the nodes during the time of the node is unavailable, when the node comes back online, it will try to compare its log index updates with the leader at that time and catch up the changes from the leader.
Q: Can a cluster become too big and slow for one leader node to replicate its changes across different follower nodes?
Yes, if the leader is in one region and the rest of the follower nodes is in another, this would be prone to network latencies and leader election may get tripped frequently. A cluster size that becomes too big will also take longer for a consensus to complete. This seems to be quite a loaded question. Below are some approaches:
- Batch processing: Instead of sending each log entry individually to the followers, the leader can batch multiple log entries together and send them in a single message. This can reduce the overhead of communication and improve the overall performance of the system.
- Leader election optimization: The Raft leader election process can be optimized to reduce the time it takes to elect a new leader in the event of a failure. For example, the system can use a randomized timeout to minimize the likelihood of multiple nodes initiating an election at the same time.
- Read-only queries: Read-only queries can be processed by any node in the Raft cluster, rather than requiring the leader to handle them. This can help to reduce the load on the leader node and improve the overall performance of the system.
- Caching: The system can use caching to improve the performance of read and write operations by reducing the need to access the disk or network for each request. Caching can be implemented at the client or server side, and can significantly improve the overall performance of the system.
- Partitioning: The Raft cluster can be partitioned into smaller sub-clusters, each with its own leader node. This can help to distribute the workload and reduce the overhead of communication between nodes. However, partitioning can introduce additional complexity and must be carefully managed to ensure that the system remains consistent and fault-tolerant.
- Hardware optimization: The hardware infrastructure of the Raft cluster can be optimized to improve performance. For example, faster network connections, more powerful servers, and solid-state drives (SSDs) can all help to reduce latency and improve the overall performance of the system.
- Multi Raft – A Multi Raft cluster consists of multiple Raft clusters that operate independently of each other, but are coordinated by a higher-level component, such as an orchestrator or load balancer. This is typically provided out of the box for productionized solutions like Kafka, CockroachDB, with possible usage of Zookeeper and other orchestrators. It would be good to understand how it is being used by some of the solutions though.
References:
- https://en.wikipedia.org/wiki/Raft_(algorithm)#Approach_of_the_consensus_problem_in_Raft – Wiki
- http://thesecretlivesofdata.com/raft/ – Visualizations
- https://raft.github.io/ – Github
- https://raft.github.io/raft.pdf – Raft white paper

Leave a comment