
- For horizontal scaling solutions, data are spread across many different servers vs in vertical scaling solutions, the data is stored in one big server.
- Horizontal scaling requires a way to identify where the data can be stored and then searched after it is stored.
- Simple Hashing Algorithms like HashMap cannot be used directly as it assumes the number of servers are fixed length size. This is known as “Rehashing Problem”.
- fn(key) mod N – where “key” is the data key name and “N” is the number of servers.
- Consistent Hashing addresses the challenge when a number of servers within a cluster gets added/removed.
- When new server gets added, majority of the data stored in the old servers still retains the data. Only small amount of data needs migration for servers that are close to the newly added server in the Hash Ring.
- When existing server gets removed, the Hashing Algorithm would map to server that gets removed for some calls initially. However if a replication policy is enforced, it would still pick up the data from other existing servers – the the next available server in the Hash Ring
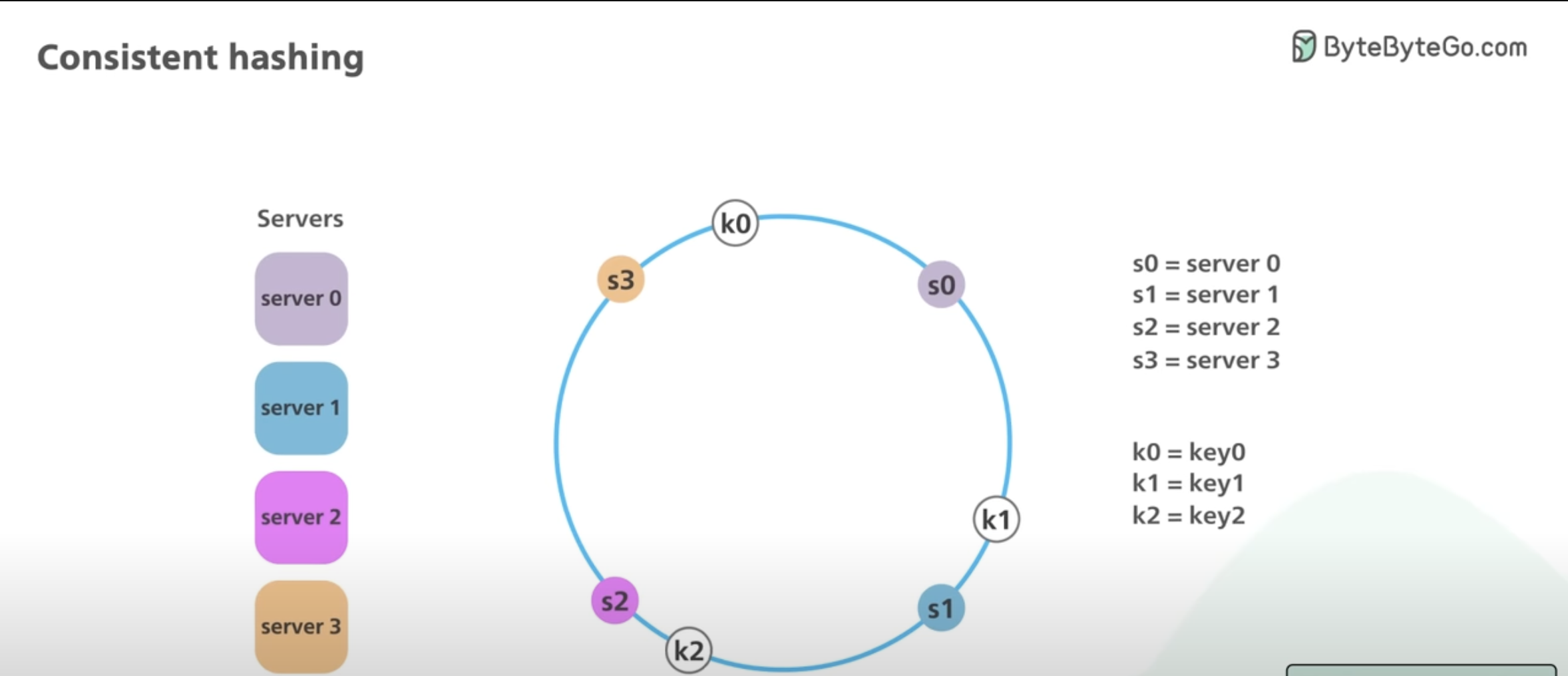
- Consistent Hashing Algorithm uses two piece of input information to compute the location of the data
- Key Name – This could be the primary key name or unique key
- Server Name – This could be the IP Address of the server, but IP Addresses can be reused, so some name with random generated characters might be more preferred.
Hash Ring Concept
- This is similar to Ring Buffer. Servers 1, 2, 3, 4 are represented in a Hash Ring. The Hash Ring simply cycles through the servers in a loop to determine where the data is located.
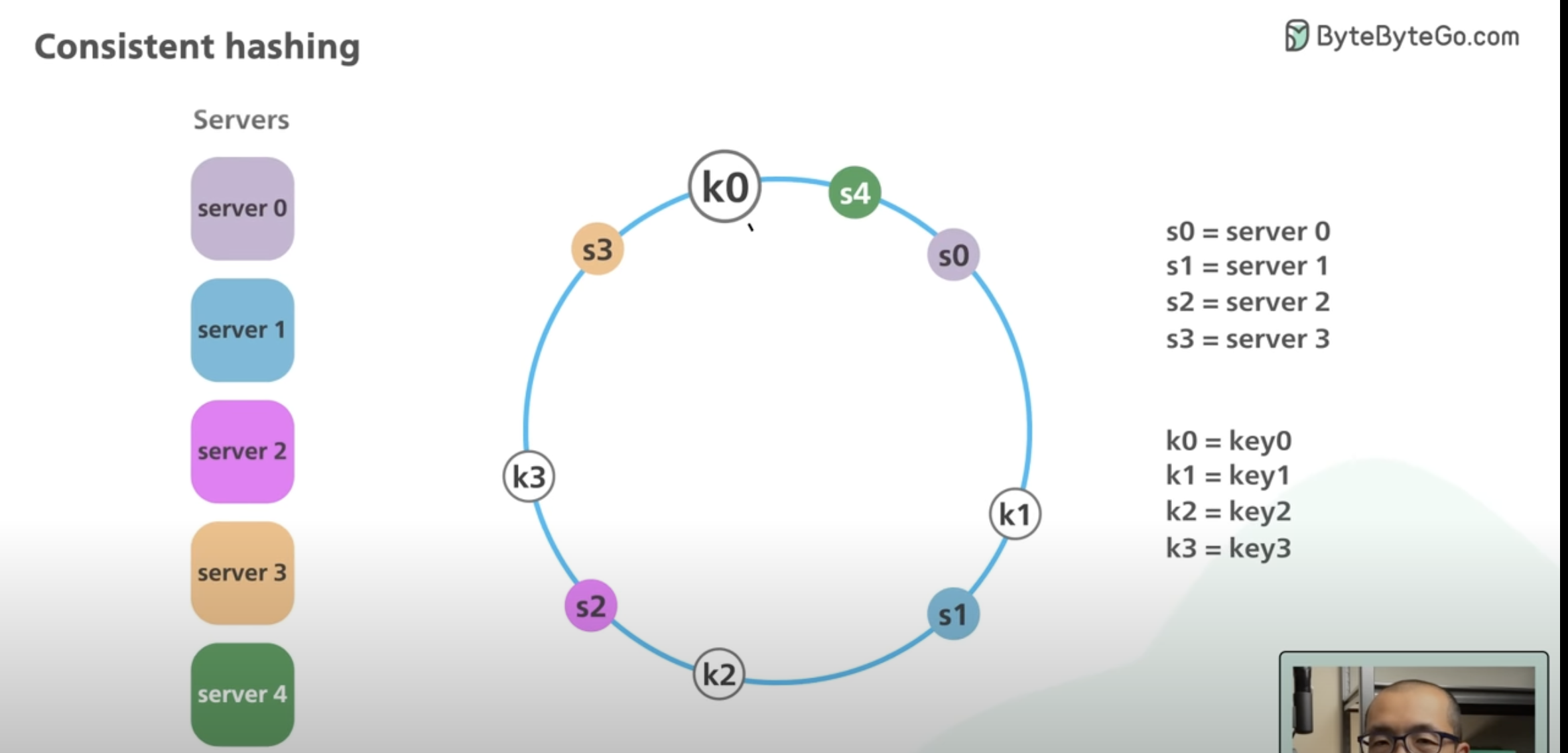
- Key 0 is currently assigned to Server 0. When a new server is added such as Server 4, Key 0 is now migrated from Server 0 to Server 4.
Consistent Hash Pitfalls
- #1 Pitfall is uneven distribution of keys to the servers – Uneven distribution can cause some servers to be overutilized, and some under utilized.
- This can be mitigated by adding more “virtual nodes” to the Hash Ring that further evenly distributes the “location” of the same server within the Hash Ring.
- High Key Churn – When keys are added or removed, the mapping of keys to servers needs to be updated, which can lead to significant overhead.
- To mitigate this, some consistent hashing algorithms use techniques such as lazy updates or incremental updates to minimize the amount of remapping required.
- Cascading Neighbor Failure Nodes – This starts by when one particular node failed in the Hash Ring and its data need to be re-migrated to the the neighbor nodes. If the neighbor is no able to handle the data migration during high volume transaction times, it can lead to a snowball effect of failures of the overall cluster.
- To mitigate this, make sure the transfer of data is as efficient as possible.
Data stores that uses Consistent Hashing
- Cassandra
- Riak
- Memcached
- Amazon DynamoDB
- Couchbase
- Voldemort
- ScyllaDB
- OrientDB
Alternatives
- Rendezvous Hashing – will write about this in the upcoming article
References:
- https://www.youtube.com/watch?v=UF9Iqmg94tk – video on consistent hashing
- https://www.toptal.com/big-data/consistent-hashing – written form about consistent hashing
- https://medium.com/i0exception/rendezvous-hashing-8c00e2fb58b0 – Rendezvous Hashing
- https://ably.com/blog/implementing-efficient-consistent-hashing#how-to-implement – Efficient consistent hashing

Leave a comment