- While its counter part “Consistent Hashing” first appeared on a May 1997 paper and is considered to be a conventional wisdom to use today Rendezvous hashing was created just one year earlier in the paper in 1996.
- Works well for load balancers, caches, and cdns mainly to distribute loads randomly when new servers are added or removed
- Not great as an algorithm for long term data storage consistency use cases – when server is removed or added, it is likely the mapped data is also removed or unable to relocate. The remediation options are all expensive.
- Replica logic might be able to remediate this but storage would drastically increase
- The algorithm itself is also not suited for medium to large clusters as it may use O(N). A variant called “Hierarchal Rendezvous Hashing” would need to be used to reduce this complexity to O(logN)
- When adding servers, we need to scan through all the keys to compute the the Highest Random Weight Hashing again in case the new servers suddenly becomes the first priority.
Rendezvous Hashing (Also known as Highest Random Weight Hashing)
- First we use the “Key” and the “Server” information as an input. To introduce some randomness, we can incorporate a seed value or salt.
- We do this for all servers with the Key. Ex: Key + S1, Key + S2, Key + S3, Key + S4 combinations to get a list of hashed values. These values can be interpreted as numerical weights for each key
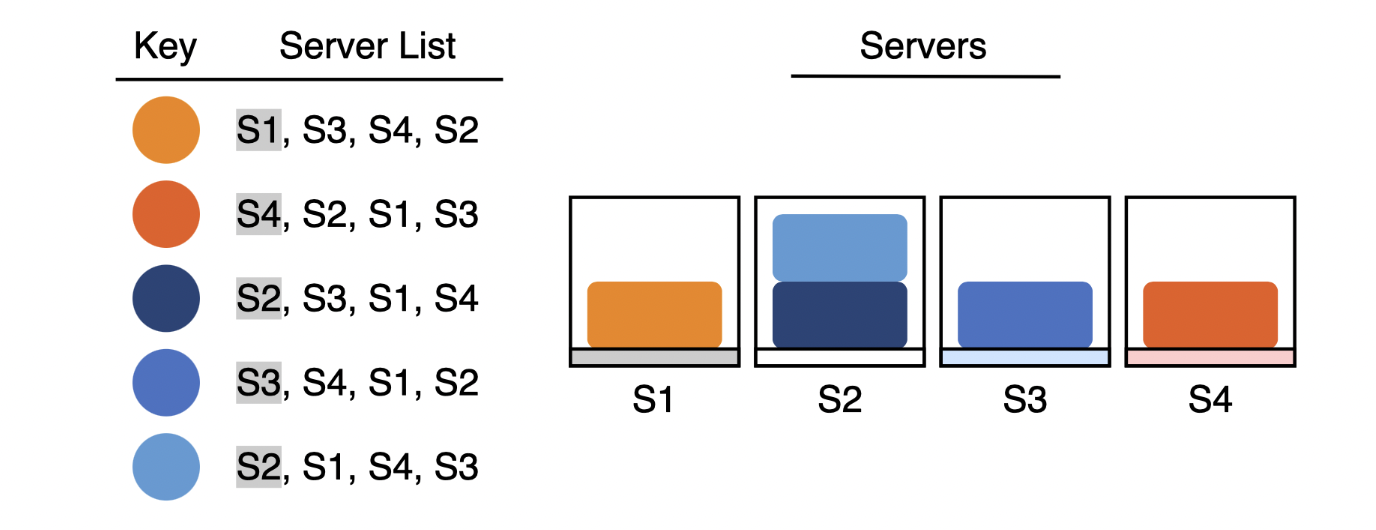
- We sort the values of a given key from biggest to smallest. Now the biggest value would be the first priority when this same key need to be accessed in the future

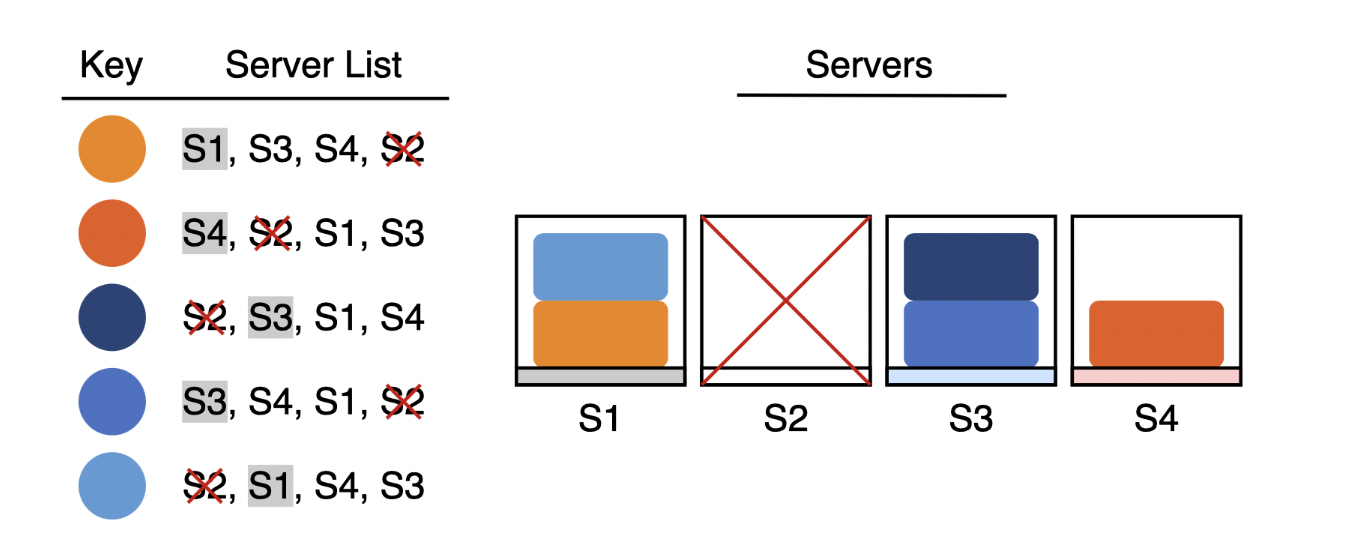
- If an existing server is removed, it would also be removed from the list of computed list and the following server would move up.
- If a new server is added, the server list would have the new server and it could also be randomly added as the first priority with some random chance.
Python Snippet
- There is another variant called “hierarchical rendezvous hashing” which basically organises the nodes into a tree like structure. This is to address the time complexity when computing the Key’s Priority server list which is O(N) to -> O(logN).
With the above explanation, it seems the use of rendezvous hashing is quite limited. Below are some real world examples:
- Twitter Pub/Sub System uses Rendezvous Hashing to improve Kafka GCs for long term client streaming use cases.
- Github Load balancer to distribute loads evenly
- Apache Ignite to split/partition data evenly
Other Hashing Algos
- Jump
- Multiprobe
- Maglev
- CHash
- Ketama
References:

Leave a comment