- Grab processes millions of orders per day. At the rate of their scale, they encountered reliability and cost issues.
- Design goals (rephrasing some things):
- High availability – even when DB has certain failure, it should always be online with some degraded experience
- HIgh Write and Read throughput
- Scalable without high cost
- Strong consistency for transactional query, and eventual consistencies for analytical queries.
- Previous solution was also DynamoDB and AuroraDB with Mysql that kept data forever.
- The new solution was not a big change, it is better management of data.
OLTP
- Transactional data like create orders, placing orders. Usually very specific records
- Write queries:
- a. Create an order.
- b. Update an order.
- Read queries:
- a. Get order by id.
- b. Get ongoing orders by passenger id.
- Write queries:
- High write throughput. Do not need to contain storage data longer than a month
- Continue to use DynamoDB with features like
- Primary key to find key values
- Sort Key to do range searching and aggregations
- Global Secondary Index – linked to main table for eventual consistency
OLAP
- Analytical data that looks at historical patterns
- Read Quries:
- c. Get historical orders by various conditions.
- d. Get order statistics (for example, get the number of orders)
- Read Quries:
- Not as business critical use cases at OLTP query patterns.
- Longer storage periods than OLTP, low writes, high reads.
- Switched from Aurora Mysql to RDS Mysql
- Cheaper and don’t need as much HA.
- Aurora Charge by storage and qps
- RDS Charge by Storage and instance size
- MySQL partitioning per month
- Partitions older than 6 months are dropped
- Data access patterns are usually monthly basis
Final Data ingestion pipeline
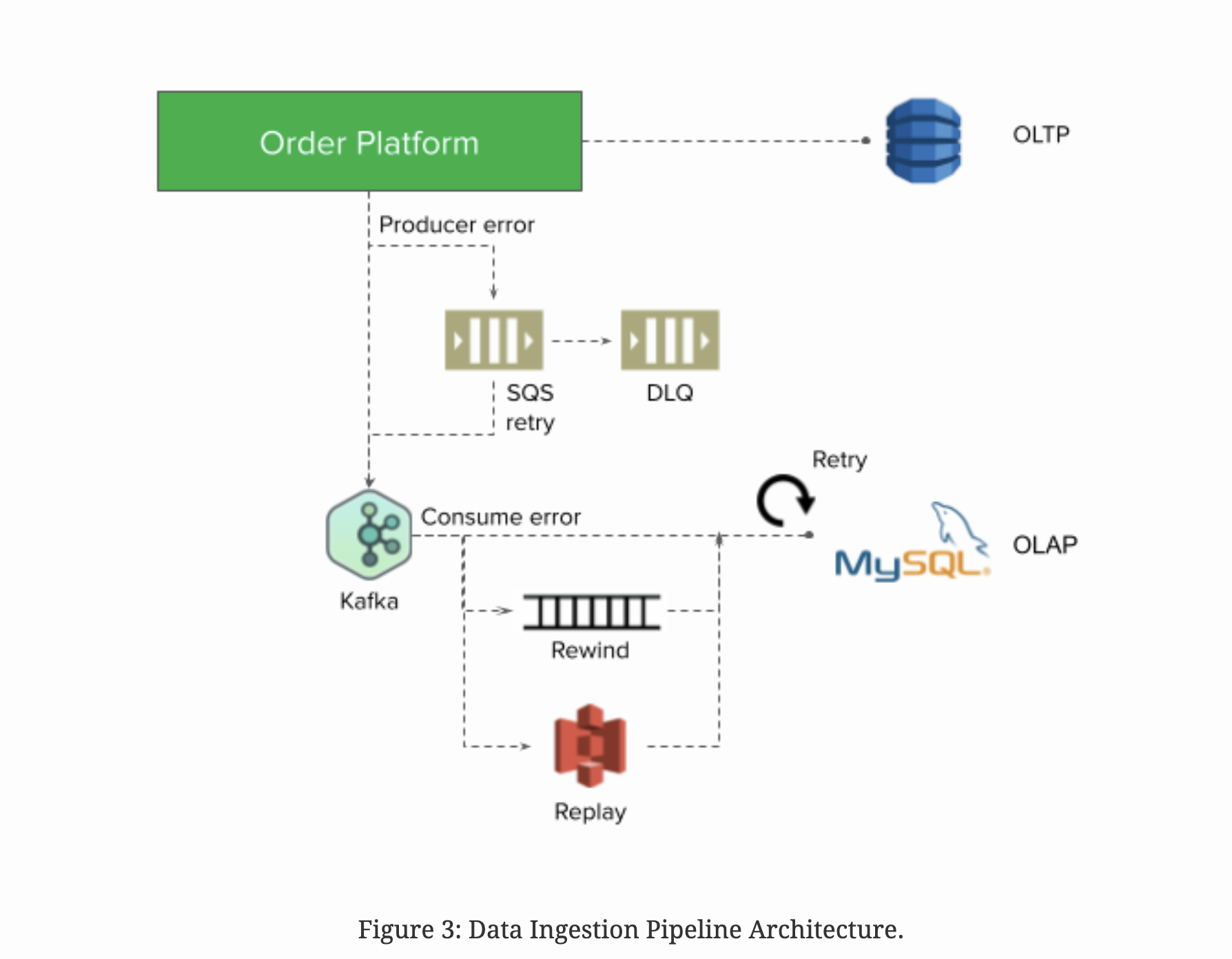
Personally not sure about the reason for introducing Kafka. Maybe there are other clients besides MySQL
Implemented Client side out of order message updates:
- Version update: we only update the most recently updated data. The precision of the update time is in microseconds, which is enough for most of the use cases.
- Upsert: if the update events occur before the create events, we simulate an upsert operation.
Takeaways:
- Design Goals are achieved. Cost of infrastructure is saved from pruning unused/inactive data.
- Thinking about Elastic Search in future to fit certain search capabilities.
Ref:

Leave a comment